排序
排序
选择排序
时间复杂度(O(N^2)) 额外空间复杂度O(1)
第一步将0-(n-1)中最小与0号交换,第二步将1-(n-1)中最小与1号交换
public static void selectsort(){
for(int i = 0; i < arr.length - 1; i++){//i到n-1
int minIndex = i;
for(int j = i + 1; j < arr.length; j++){
minIndex = arr[j] < arr[minIndex] ? j : minIndex;
}
swap(arr, i, minIndex);
}
}
public static void swap(int[] arr, int i, int j){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}了解位运算

关键:异或运算:偶数个1为结果0;奇数个结果为1
1)一组数,一个数出现了奇数次,其他为偶数次,求出该数
//所有数异或一遍
public static void Num1(int arr[]){
int eor = 0;
for(int cur : arr){
eor ^= cur;
}
}2)一组数,两个数出现了奇数次,其他偶数次,求该两数
提取出最右边的1:取反加1并&原数
//完成后eor=a^b
public static void Num1(int arr[]){
int eor = 0;
for(int cur:arr){
eor ^= cur;
}
//完成后,eor'是a或者b
//因为eor'选择的是a b同位置不同1 0的数,a b一定分别在一组中
//提取最右边的1
int rightone = eor & (~eor+1);
//再让eor‘和eor异或得到另一数
int onlyone = 0;
for(int curr:arr){
if ((cur & rightone) == 1) {//0也可
onlyone ^= cur;
}
}
}冒泡排序(注意交换的方法—位运算)
时间复杂度(O(N^2)) 额外空间复杂度O(1)
第一步将0-(n-1)中最大移到最右边,每次对比相邻两数,第二步将0-(n-2)中最大移到最右边
public static void bubblesort(){
for(int i = arr.length - 1; i > 0; i--){//0到i
for(int j = 0; j < i; j++){
if(arr[j] > arr[j + 1]){
swap(arr, j, j+1);
}
}
}
}
//这样玩的前提是内存地址两个数
public static void swap(int[] arr,int i,int j){
arr[i] = arr[i] ^ arr[j];
arr[j] = arr[i] ^ arr[j];
arr[i] = arr[i] ^ arr[j];
}插入排序
时间复杂度(O(N^2)) 额外空间复杂度O(1)
第一步0-0有序,第二步让0-1有序......每次让小的去左边
public static void insertsort(){
for(int i = 1; i < arr.length; i++){//0-i想有序
//也可以让j=i,但需要修改for中的条件
for(int j = i - 1; j >= 0 && arr[j] > arr[j+1]; j--){
//i位和i-1比较
swap(arr,j,j+1);
}
}
}
public static void swap(int[] arr, int i, int j){
arr[i] = arr[i] ^ arr[j];
arr[j] = arr[i] ^ arr[j];
arr[i] = arr[i] ^ arr[j];
}归并排序
时间复杂度(O(N*logN)) 额外空间复杂度O(N)
1.整体就是一个简单递归,左边有序,右边有序,整体有序
2.整体有序的过程用了外排序方法
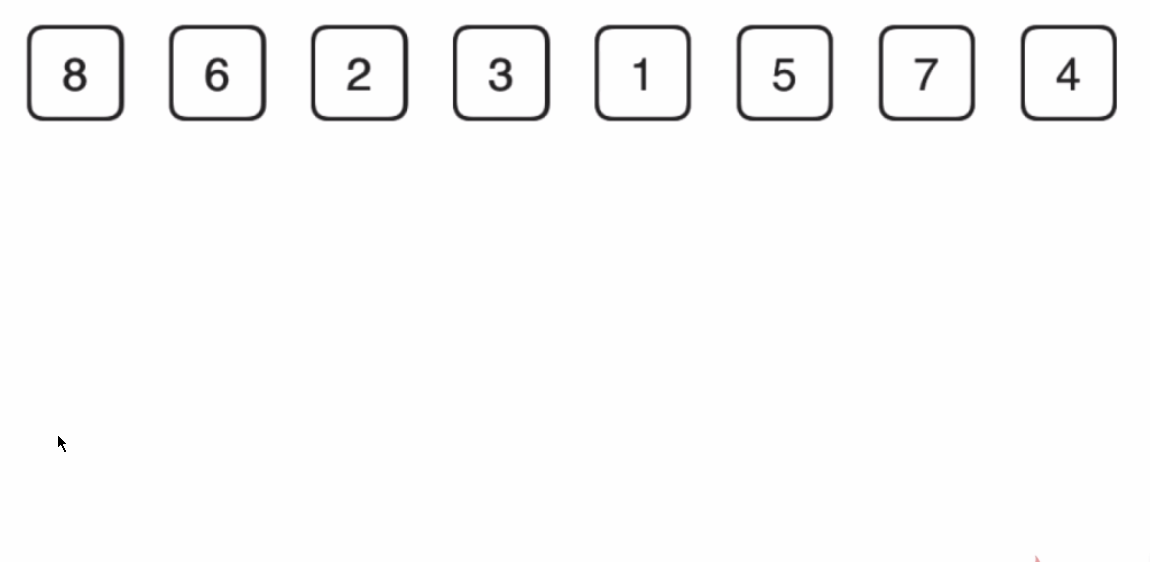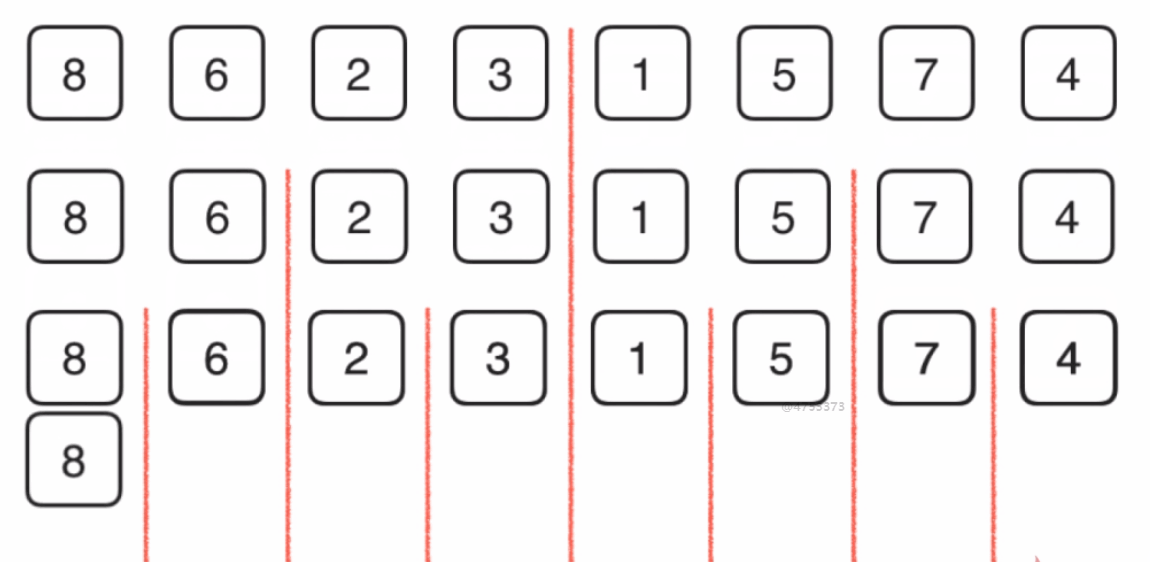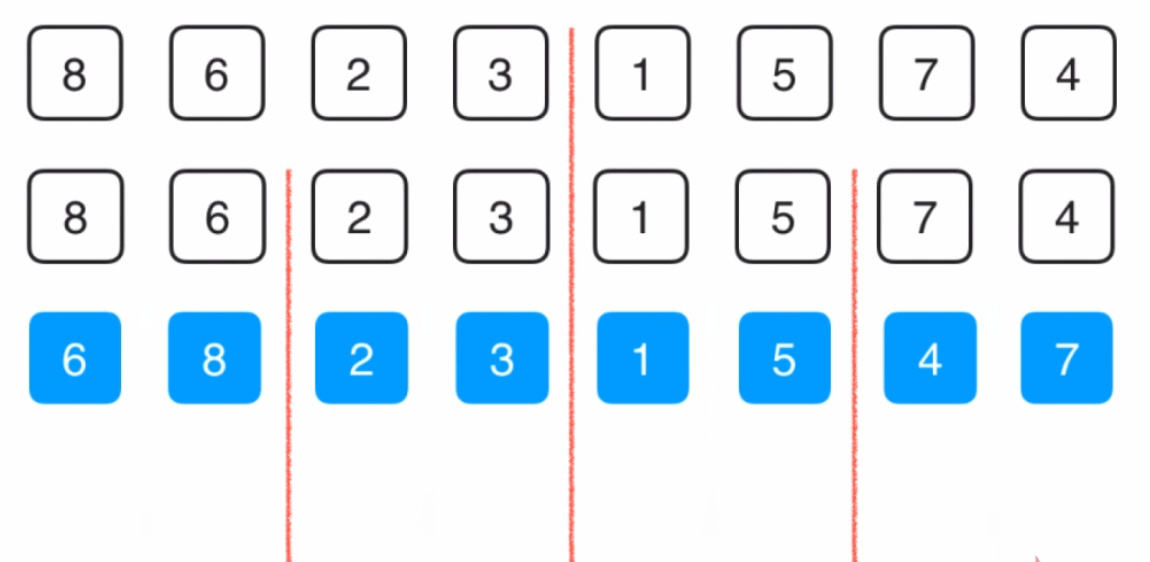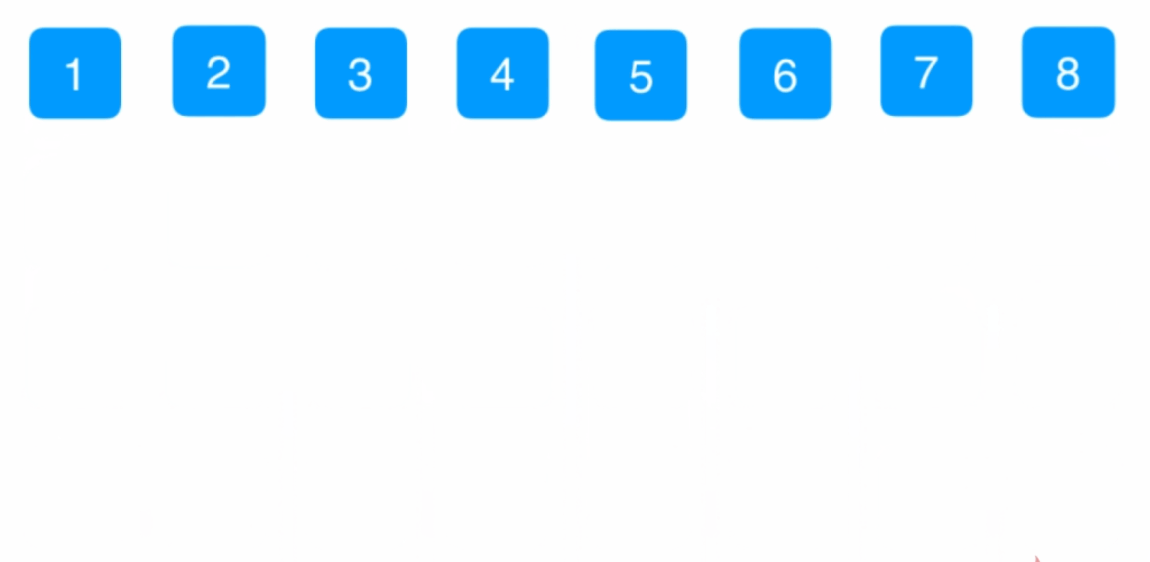
递归实现
public static void process(int[] arr, int L, int R){
if(L == R) return;
int mid = L + ((R-L) >> 1);
process(arr, L, mid);
process(arr, mid+1, R);
merge(arr, L, mid, R);
}
public static void merge(int[] arr, int L, int M, int R){
int[] help = new int[R - L + 1];
int i = 0;
int p1 = L;
int p2 = M+1;
while(p1 <= M && p2 <= R){
help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];
}
while(p1 <= M){
help[i++] = arr[p1++];
}
while(p2 <= R){
help[i++] = arr[p2++];
}
for(i = 0; i < help.length; i++){
arr[L + i] = help[i];
}
}小和问题
在一个数组中求出所有数的左边比它小的数的和
解题思路:
很容易想出暴力解法,即遍历每一个数并遍历他前面的元素去累加小数,时间复杂度差,为O(N^2)。
其实借助归并排序的思想可以把这个时间复杂度降到O(NlogN)
转换问题为求一个数右边有多少个比他大的

注意,当右组等于左组,先拷贝右组,这是和原版的归并排序的区别,这样才能知道右组有几个数比左组的数大
public static int smallSum(int[] arr) {
if(arr == null || arr.length <= 1) {
return 0;
}
return process(arr, 0, arr.length - 1);
}
// 递归函数
// 既能排序又能求出小和
public static int process(int[] arr, int l, int r) {
if(l == r) return 0;
int m = l + ((r - l) >> 1);// 防溢出
return process(arr,l,m)
+ process(arr,m + 1,r)
+ merge(arr, l, m , r);
}
// 归并函数
public static int merge(int[] arr, int l, int m, int r) {
int[] help = new int[r - l + 1]; // 辅助数组
int i = 0;
int p1 = l;
int p2 = m + 1;
int res = 0;
while(p1 <= m && p2 <= r) {
//注意没有等于
res += arr[p1] < arr[p2] ? arr[p1] * (r - p2 + 1) : 0;
help[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];
}
while(p1 <= m) {
help[i++] = arr[p1++];
}
while(p2 <= r) {
help[i++] = arr[p2++];
}
for(int j = 0; j < help.length; j++) {
arr[l + j] = help[j];
}
return res;
}
//其实可以看到除了递归累加和第一个while中对于小数和计算的逻辑,和归并排序一模一样!逆序对问题
左边的数如果比右边的数大,则折两个数构成一个逆序对
和上方的小和问题几乎相同,只是大小要求不一样
非递归实现-迭代实现
// 归并排序迭代实现
public static void mergeSort02(int[] arr) {
if(arr == null || arr.length <= 1) {
return;
}
int n = arr.length;
int mergeSize = 1; // 步长,初始化为1
while(mergeSize < n) { // 不断2倍地调整步长,最多logn
int l = 0;
while(l < n) {
if(mergeSize >= n - l) { // 如果mergeSize=n-l时,m=n-1,右边数组没有元素,直接跳出while循环
break;
}
int m = l + mergeSize - 1;
int r = m + Math.min(mergeSize, n - m - 1); // 边界限制,最多到n-1
merge(arr, l, m, r); // 依旧调用之前的merge函数进行归并
}
if(mergeSize > n / 2) { // 当步长比 n / 2都大时,直接停止,翻译出
break;
}
mergeSize <<= 1; // mergeSize翻倍
}快速排序
时间复杂度(O(N^logN)) 额外空间复杂度O(logN)
快排1.0
用范围最后一个数当划分值,每次确定一个数的位置,直到完成全部
**时间复杂度(O(N^2)) **
思路:一个划分值,他左边是小于等于他的,右边是大于他的,每次可以确定划分值的位置,每次的划分值选择该范围最后一个数,每一次确定一个数的位置
小于等于区一开始指向-1,然后右扩

public static int partSort(int[] arr,int left,int right){
/*if (left > right) {
return -1;
}*/
if (left == right) return left;
int sbegin = left - 1;
//while也可以
/*
while (i < r) {
// 如果当前元素小于等于划分值arr[r],则和<=区域的右边元素交换,并让<=区域向右扩大一位
if(arr[i] <= arr[r]) {
swap(arr,i,++lessEqual);
}
i++;
}
// 到这里为止arr[r]没动过,都交换完毕后将arr[right]和<=区域右边一个元素做交换
swap(arr,r,++lessEqual);
*/
for (int i = left; i <= right; i++){
if (arr[i] <= arr[right]) {
swap(arr, ++sbegin, i);
}
}
//这里不需要swap(arr, r, ++sbegin);了。因为上述for循环的最后一次完成了这个任务
return sbegin;
}
public static void quickSort(int[] arr, int l, int r) {
if(l >= r) {
return;
}
// 获得划分值下标
int p = partSort(arr, l, r);
// 根据划分值下标递归调用划分函数对左右 <= 和 > 两部分进行划分
quickSort(arr,l,p - 1);
quickSort(arr, p+ 1, r);
}
public static void swap(int[] arr, int i, int j){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}快排2.0
**时间复杂度(O(N^2)) **
增加等于区域,每次确定一个范围,比1.0要快一些

public static int[] partition(int[] arr, int l, int r) {
// 如 l > r 越界,则返回数组[-1,-1]
if(l > r) {
return new int[] {-1, -1};
}
// 如 l == r,说明待分割数组只有一个元素,直接返回[l, r]
if (l == r) {
return new int[] {l, r};
}
int less = l - 1;
int more = r;
//用for循环做会复杂一点
/*for (int i=l;i<more;i++){
if (arr[i]<arr[r]){
swap(arr,++less,i);
}else if (arr[i]==arr[r]){
//swap(arr,++less,i);
}else{
//注意这里i--了,因为换过来的数没有经过和划分值比大小
swap(arr,--more,i--);
}
}*/
int i = l;
while (i < more) {
if(arr[i] == arr[r]) {
i++;
} else if (arr[i] < arr[r]) {
swap(arr,i++, ++less);
} else if(arr[i]> arr[r]) {
//注意这里i没有++,因为换过来的数没有经过和划分值比大小
swap(arr, i,--more);
}
}
swap(arr,r,more);
return new int[] {
less + 1, more
};
}
public static void swap(int[] arr, int a, int b) {
int t = arr[a];
arr[a] = arr[b];
arr[b] = t;
}
public static void quickSort(int[] arr, int l, int r) {
if(l >= r) {
return;
}
int[] flag = partition(arr,l,r);
quickSort(arr, l, flag[0] - 1);
quickSort(arr,flag[1] + 1, r);
}快排3.0
时间复杂度(O(N^logN)) ,差为N方
额外空间复杂度O(logN),差为N
只需要在2.0版本的int[] 上方加一句交换语句,随机生成一个位置
public static void quickSort(int[] arr, int l, int r) {
if (l >= r) {
return;
}
swap(arr, r, (int) Math.random() * (r - l + 1));
int[] flag = partition(arr, l, r);
quickSort(arr, l, flag[0] - 1);
quickSort(arr, flag[1] + 1, r);
}堆排序
堆
堆在应用层面叫做优先队列(PriorityQueue)
堆本质上就是个完全二叉树,分为大根堆和小根堆,如下图所示:
大根堆就是每个子树的根节点都是它所在子树中最大的,小根堆同理
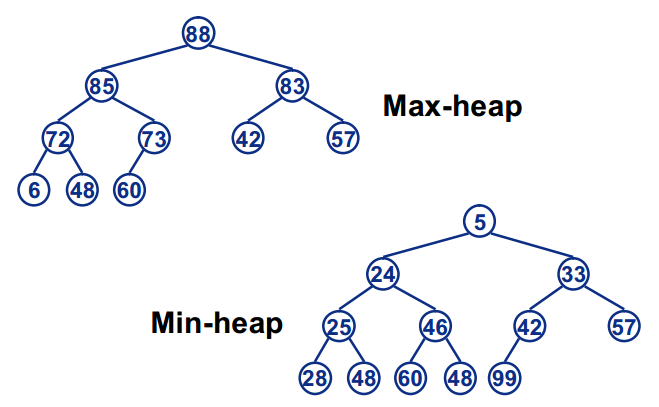
从0开始可以将数组模拟成完全二叉树
也可以选择数组0位置置空,从1开始存储,但是数组的下标对应左右孩子映射关系会变化
左孩子 2i
右孩子2i+1
父亲i/2
i位置
**左孩子 2i+1 **
**右孩子2i+2 **
父亲(i-1)/2
heapInsert过程
public static void heapInsert(int [] arr, int index){
while (arr[index] > arr[(index - 1) / 2]){
//不比父亲大或者来到头位置(0位置)停止
swap(arr, index, (index - 1)/2);
index = (index-1)/2;
}
}heapfy过程
返回并去掉堆中最大值,让剩余数字重新构成堆
步骤:1.保存最大值并让最后一个数覆盖顶点
2.从顶点开始和他的左右比,同时左右也对比谁大,和大的交换,不断循环到不交换
public static void heapfy(int[] arr,int index,int heapsize){
int left = 2 * index + 1;
//while条件代表至少有左孩子
while(left < heapsize){
//两个孩子中,谁的值大就把Index赋值给largest
//第一个条件代表有右孩子
int largest = (left + 1 < heapsize && arr[left + 1] > arr[left]) ? left + 1 : left;
//父亲和较大孩子之间谁大谁给largest
largest = arr[largest] > arr[index] ? largest : index;
if(largest == index){ break;}
swap(arr, largest, index);
index = largest;
left = 2 * index + 1;
}
}下标从1开始的版本
重点在于left <= size和left+1<=size
void heapfy(int arr[],int index,int size){
int left = 2 * index;
//注意和0开始的下标的区别left < size 和 left <= size
while(left <= size){
//两个孩子中,谁的值大就把Index赋值给largest
//注意和0开始的下标的区别left+1 < size 和 left+1 <= size
int largest= (left + 1 <= size) && arr[left+1]>arr[left]
? left+1 : left;
//父亲和较大孩子之间谁大谁给largest
largest = arr[largest] > arr[index] ? largest : index;
if(largest==index){ break;}
swap(arr,largest,index);
index=largest;
left=2*index ;
}
}heapInsert和heapfy结合使用
将堆中某个数改为?,如果问号比原来的小,向下heapfy过程,如果比原来的大,向上heapInsert过程
调整代价
因为堆的高度最高为logN,在调整堆时调整路径可以看作一条线,最多logN,所以调整堆的时间复杂度为O(logN)
直接初始化(不是用insert一个个插入)
下标从1开始的版本
void initialiize(int arr[],int len){
for (int root = len / 2; root >= 1 ; root--) {
int ele = arr[root];
int child = 2 * root;
while (child <= len){
if (child < len && arr[child] < arr[child + 1]) child++;
if (ele >= arr[child]) break;
arr[child / 2] = arr[child];
child *= 2;
}
arr[child / 2]= ele;
}
}排序实现
时间复杂度(O(N^logN)) 额外空间复杂度O(1)
思路:先建立大根堆,然后不断最后一位和头位置交换并heapfy过程
public static void heapSotr(int[] arr){
if(arr==null||arr.length==1) return;
for(int i=0;i < arr.length;i++){
heapInsert(arr,i);
}
int heapSize = arr.length;
swap(arr,0,--heapSize);
while(heapSize>0){
heapfy(arr,0,heapSize);
swap(arr,0,--heapSize);
}
}下标从1开始的版本
void heapSotr(int arr[],int length){
if(arr==NULL || length==1) return;
int heapSize = length;
swap(arr,1,heapSize--);
while(heapSize>0){
heapfy(arr,1,heapSize);
swap(arr,1,heapSize--);
}
}java类库中的堆
优先队列(PriorityQueue)
PriorityQueue<Integer> heap = new PriorityQueue<>();系统的堆就是一种黑盒,但是不够高效,黑盒只能add和poll,无法高效的做到某些操作,比如,将一个数更改后仍然保持堆结构
不基于比较的排序
计数排序-桶排序的一种
统计每个数的词频,适用范围比较差,它在一些数据特殊(要求样本是整数并且范围比较窄)的情况下效率很高
/**
* 计数排序-以员工年龄数组为例
* @param ageArr
*/
public static void CountSort(int[] ageArr) {
// 不需要排序的情况
if(ageArr == null || ageArr.length <= 1) {
return;
}
// 声明最大值并初始化
int max = 0;
// 遍历数组更新最大值
for (int i = 0; i < ageArr.length; i++) {
max = Math.max(max, ageArr[i]);
}
// 定义桶
int[] buckets = new int[max + 1];
for (int i = 0; i < ageArr.length; i++) {
buckets[ageArr[i]]++;
}
int j = 0;
for (int i = 0; i < buckets.length; i++) {
while(buckets[i]-- > 0) {
ageArr[j++] = i;
}
}
}基数排序-桶排序的一种
10个桶,0 1 2 3 ......
和计数排序不同,基数排序的一个桶中装的不是相同的数,并且为了保证排序稳定性要保证桶中的数据是先入先出的,所以我们可以使用队列做桶,但是10个队列的写法不是很优雅,有一种优化桶写法就是借助当前位词频的前缀累加和数组:
比如我们我有整数数组[111、1、22、31、50]
词频统计数组:[1、3、1、0、0、0、0、0、0、0] (注意一位数的范围是0~9)
词频统计前缀和数组:[1、4、5、5、5、5、5、5、5、5]
有了统计词频的前缀和数组后用右向左遍历原数组填数,首先是50,此时50的个位数0对应的词频为1,所以50应填在(1-1)=0的位置上,数组情况:[50]
然后是31,此时1对应的词频为4,所以31应放在下标为3的位置上,[50,0,0,31]
之后同理,数组变成了[50,111,1,31,22],不需要10个桶,只需要两个长度为10的辅助数组,数组就按照个位数+维持稳定性排好序了~
总结:从后向前遍历数组模拟了队列先进先出,后进后出的过程,不需要队列了
//经典基数排序-函数入口
public static void radixSort(int[] arr) {
if(arr == null || arr.length <= 1) {
return;
}
radixSort(arr, 0, arr.length - 1, maxbit(arr));
}
//基数排序实现函数
private static void radixSort(int[] arr, int left, int right, int maxbits) {
// 以 10 为基数
final int radix = 10;
// 需要的辅助空间
int[] bucket = new int[right - left + 1];
for (int i = 1; i <= maxbits; i++) {//最大数有几位就进出几次
int[] count = new int[radix];
// 词频统计
for (int j = left; j <= right; j++) {
count[getDigit(arr[j], i)]++;
}
// 计算词频前缀和
for(int k = 1; k < radix; k++) {
count[k] += count[k - 1];
}
// 从右往左遍历填数
for(int k = right; k >= left; k--) {
int d = getDigit(arr[k], i);
bucket[count[d] - 1] = arr[k];
count[d]--;
}
// 将辅助数组复制到原数组中
for (int k = 0, q = left; k < bucket.length; q++, k++) {
arr[q] = bucket[k];
}
}
}
// 获取一个数对应位数上的数值
public static int getDigit(int t, int d) {
return ((t /(int) Math.pow(10,d - 1)) % 10);
}
// 返回一个数组中数的最多位数
private static int maxbit(int[] arr) {
int max = Integer.MIN_VALUE;
for (int i = 0; i < arr.length; i++) {
max = Math.max(max, arr[i]);
}
int res = 0;
while (max > 0) {
max /= 10;
res++;
}
return res;
}稳定性和总结
排序稳定性
排序算法的稳定性:
稳定性是指同样大小的样本再排序之后不会改变相对次序,通俗来说就是相同的值排序后不改变相对次序就是稳定的。
对于基础类型来说,稳定性毫无意义,比如int类型相同值排前面和排后面,整体的排序结果是一样的。
对于非基础类型(比如Java中自己定义的类),稳定性有重要的意义。
有些排序算法可以实现成稳定的,而有些无论如何都实现不成稳定的
可以实现稳定的排序
冒泡排序,如果在冒泡过程中遇到相等的情况时不交换,即可实现稳定性
插入排序,保存之前的顺序进行插入
归并排序,先拷贝归并过程中左子数组
不可能实现稳定性的排序
选择排序,交换过程一定会破坏稳定性
快速排序,荷兰国旗划分函数中的元素交换过程就会破坏稳定性
堆排序,第一步建堆中的交换过程就会破坏稳定性
总之,排序算法的稳定性其实是比较重要的考虑因素,这就是有的时候快排的速度明明比归并排序快,而却选用归并排序,就是因为归并排序具有稳定性而快排不具备稳定性。
| 时间 | 空间 | 稳定性 | |
|---|---|---|---|
| 选择 | O(N^2) | O(1) | × |
| 冒泡 | O(N^2) | O(1) | √ |
| 插入 | O(N^2) | O(1) | √ |
| 归并 | O(N^logN) | O(N) | √ |
| 快排(随机) | O(N^logN) | O(logN) | × |
| 堆 | O(N^logN) | O(1) | × |
| 计数 | O(N+k) | O(k) | √ |
| 基数 | O(N+k) | O(N+k) | √ |
工程上对排序的改进
1、对稳定性的考虑
比如 Java 中的Arrays.sort(),在排序时根据数据类型有两种算法选取的情况:
- 发现是基础类型,不需要考虑稳定性,底层会走快排(快排速度>归并排序)
- 不是基础类型,需要考虑稳定性,底层走归并排序
2、充分利用O(NlogN)和O(N^2)排序各自的优势
比如插入排序,它的时间复杂度为O(N^2),但是常数项小,而快排的时间复杂度为O(NlogN),但是常数项高。
所以当排序区间小于一定范围时使用插入排序会更优,N大用快排,N小可以用插排,一般以 60 为界(经过实验得到)。