图
图
存储方式
邻接矩阵
邻接表法
图的表达方式有很多,关键在于将不熟悉的结构转换为自己擅长的,写过的,只需要写一个转化即可
图的定义
各种图的表示都可以用这种方式来表示,在应用时只需要将陌生的图表示方法,转换成当前这种方式
public class Graph{
public HashMap<Integer,Node> nodes;
public HashSet<Edge> edges;
public Graph() {
nodes = new HashMap<>();
edges = new HashSet<>();
}
}
//Node
public class Node{
public int value;
public int in;
public int out;
public ArrayList<Node> nexts;//从自己指出去的点
public ArrayList<Edge> edges;//从自己指出去的边
public Node(int value){
this.value = value;
in = 0;
out = 0;
nexts = new ArrayList<>();
edges = new ArrayList<>();
}
}
//Edge
public class Edge{
public int weight;
public Node from;
public Node to;
//构造器
public Edge(int weight,Node from, Node to){
this.weight = weight;
this.from = from;
this.to = to;
}
}宽度优先遍历(又称广度BFS)
从一个点出发,把它放进队列并放进set,队列弹出该节点,处理该节点,再将它的nexts全部进队列(进之前看set是否加过了)
public static void bfs(Node node){
if (node == null){
return;
}
Queue<Node> queue = new Linkedlist<>();
//set用于判断是否已经进入队列中
HashSet<Node> set = new HashSet<>();
queue.add(node);
set.add(node);
while ( queue.isEmpty() ){
Node cur = queue.poll();
Sysytem.out.println(cur.value);
//将所有的nexts放入队列和set集合
for(Node next : cur.nexts){
if( !set.contanins(next) ){
set.add(next);
queue.add(next);
}
}
}
}深度优先遍历(DFS)
从一个点开始,这个点进栈,进set,从栈弹出一个,将它的nexts进栈(进栈之前set判断),如果set没有这个next,将cur压回去,这个next也压进栈,处理next,break循环
public static void dfs(Node node){
if (node == null){
return;
}
Stack<Node> stack = new Stack<>();
HashSet<Node> set = new HashSet<>();
stack.add(node);
set.add(node);
//处理
Sysytem.out.println(node.value);
while ( !stack.isEmpty()){
Node cur = stack.pop();
for(Node next : cur.nexts){
if( !set.contanins(next) ){
stack.push(cur);
stack.push(next);
set.add(next);
//处理
System.out.println(next.value);
break;
}
}
}
}深度优先和宽度优先的区别
摘自:https://blog.csdn.net/yyuggjggg/article/details/120796567
深度优先搜索用栈(stack)来实现
广度优先搜索使用队列(queue)来实现
深度优先遍历:对任何一个分支都深入到不能再深入为止,每个节点只能访问一次。
二叉树的深度优先分为:先序遍历、中序遍历、后序遍历。具体介绍见上面的说明
宽度优先遍历:层次遍历,从上往下对每一层进行遍历,在每一层中,从左往右(也可以从右往左)访问结点,一层一层的进行点,直到没有结点为止
深度优先搜素算法:不全部保留结点,占用空间少;有入栈、出栈操作,运行速度慢。
广度优先搜索算法:保留全部结点,占用空间大; 无入栈、出栈操作,运行速度快。
拓扑排序(有向图,无环,有入度为零节点)
入度为0排在第一个,除去该点的影响,循环该过程寻找下一个入度为0
算法:1.遍历整个图,入度为0的进入队列
2.队列弹出节点,它的next的入度在map中都减1
public static List<Node> sortedTopology(Graph graph){
//key,某一个node
//value,剩余的入度
HashMap<Node, Integer> inMap = new HashMap<>();
//入度为0的点才能进入这个队列
Queue<Node> zeroqueue = new LinkedList<>();
for(Node node : graph.nodes.values() ){
inMap.put(node, node.in);
if(node.in == 0){
zeroqueue.add(node);
}
}
List<Node> result = new ArrayList<>();
while( !zeroqueue.isEmpty()){
Node cur = zeroqueue.poll();
result.add(cur);
for(Node next : cur.nexts){
inMap.put(next, inMap.get(next) - 1);
if (inMap.get(next) == 0){
zeroqueue.add(next);
}
}
}
return result;
}kruskal算法生成最小生成树
最小生成树是权值之和最小的生成
从权值最小的边开始加,加过的边锁住,如果加的边会产生环就不要,遍历完所有边即可
低配版并查集结构
public class MySet{
public HashMap<Node,List<Node>> setMap;
public MySet(List<Node> nodes){
for (Node cur : nodes){
List<Node> set = new ArrayList<Node>();
set.add(cur);
setMap.put(cur, set);
}
}
public boolean isSame(Node from,Node to){
List<Node> fromSet = setMap.get(from);
List<Node> toSet = setMap.get(to);
return fromSet == toSet;
}
public void union(Node from,Node to){
List<Node> fromSet = setMap.get(from);
List<Node> toSet = setMap.get(to);
for (Node toNode : toSet){
fromSet.add(toNode);
setMap.put(toNode, fromSet);
}
}
}并查集版本
//下面用的比较器
public static class EdgeComparator implements Comparator<Edge>{
public int compare(Edge o1,Edge o2){
return o1.weight - o2.weight;
}
}
public static Set<Edge> kruskal(Graph graph){
UnionFind unionFind = new UnionFind()
unionFind.makeSets(graph.nodes.values() );
PriorityQueue<Edge> queue = new PriorityQueue<>(new EdgeComparator());
for(Edge edge : graph.edges){
queue.add(edge);
}
Set<Edge> result = new HashSet<>();
while(!queue.isEmpty()){
Edge = queue.poll();
if(!unionFind.isSameSet(edge.from,edge.to) ){
result.add(edge);
unionFind.union(edge.from,edge.to);
}
}
return result;
}prim算法最小生成树
从一个点开始,解锁它的边,选择最小的,解锁另一个节点,然后又解锁了新的边,继续选择最小的边,用过的边不可继续使用,锁住,最后所有锁的边就是最小生成树
class EdgeComparator implements Comparator<Edge>{
public int compare(Edge o1, Edge o2){
return o1.weight - o2.weight;
}
}
public static Set<Edge> primMST(Graph graph){
//解锁的边进入小根堆
PriorityQueue<Edge> priorityQueue = new PriorityQueue<>(
new EdgeComparator()
);
HashSet<Node> set = new HashSet<>();
Set<Edge> result = new HashSet<>();
for (Node node : graph.nodes.values()) {
//上面这个for-each针对森林的问题
//node是开始点
if (!set.contains(node)){
set.add(node);
for (Edge edge: node.edges){//由一个点,解锁所有相连的边
priorityQueue.add(edge);
}
while(!priorityQueue.isEmpty()){
Edge edge = priorityQueue.poll();//弹出解锁的边中,最小的边
Node toNode = edge.to;//可能的一个新的点
if(!set.contains(toNode)){//不含有的时候,就是新的点
set.add(toNode);
result.add(edge);
//下面这个for-each循环可能视同一个边被重复添加到堆中,但是不影响结果
for (Edge nextEdge : toNode.edges ){
priorityQueue.add(nextEdge);
}
}
}
}
}
return result;
}dijkstra算法(不能有权值为负数的边,需要指定出发点)
严格来说,存在权值为负数的边也有可能可以
求最短路径
普通版
public static HashMap<Node,Integer> dijkstral(Node head) {
//从head出发到所有点的最小距离
//key: 从head出发到达key
//value: 从head出发到达key的最小距离
//如果表中没有T的记录,含义是从head到T这个点的距离为正无穷
HashMap<Node, Integer> distanceMap = new HashMap<>();
distanceMap.put(head,0);
//已经求过距离的节点,存在selected中,以后再也不碰
HashSet<Node> selected = new HashSet<>();
Node minNode = getMinDistanceAndUnselectedNode(distanceMap, selected);//从Map中选出最小的Node
while(minNode != null){
//minNode现在到指定点的距离
int distance = distanceMap.get(minNode);
for(Edge edge : minNode.edges){
Node toNode = edge.to;
if (!distanceMap.containsKey(toNode) ){
distanceMap.put(toNode, distance + edge.weight);
}else {
distanceMap.put(edge.to, Math.min(distanceMap.get(toNode),
distance + edge.weight) );
}
}
selected.add(minNode);
minNode = getMinDistanceAndUnselectedNode(distanceMap, selected);
}
return distanceMap;
}
public Node getMinDistanceAndUnselectedNode(HashMap<Node,Integer> distanceMap,HashSet<Node> touchedNodes){
Node minNode = null;
int minDistance = Integer.MAX_VALUE;
for(Entry<Node ,Integer> entry : distanceMap.entrySet(){
Node node = entry.getKey();
int distance = entry.getValue();
if (!touchedNodes.contains(node) && distance < minDistance){
minNode = node;
minDistance = distance;
}
}
return minNode;
}改进版
利用小根堆,加速选择出最小值的过程,但是本题需要自己写堆
class Node{
}
class NodeRecord{
public Node node;
public int distance;
public NodeRecord(Node node, int distance) {
this.distance = distance;
this.node = node;
}
}
class NodeHeap {
private Node[] nodes;
private HashMap<Node, Integer> heapIndexMap;//value代表对应Node在数组中的index值
private HashMap<Node, Integer> distanceMap;//value代表Node到head的距离
private int size;
public NodeHeap(int size) {
nodes = new Node[size];
heapIndexMap = new HashMap<>();
distanceMap = new HashMap<>();
this.size = 0;
}
public boolean isEmpty() {
return size == 0;
}
public void addOrUpdateOrIgnore(Node node, int distance) {
if (inHeap(node)) {
distanceMap.put(node, Math.min(distanceMap.get(node), distance) );
insertHeapfy(node, heapIndexMap.get(node));
}
if (!isEntered(node)) {
nodes[size] = node;
heapIndexMap.put(node, size);
distanceMap.put(node, distance);
insertHeapfy(node, size++);
}
}
public NodeRecord pop() {
NodeRecord nodeRecord = new NodeRecord(nodes[0], distanceMap.get(nodes[0]));
swap(0, size - 1);
heapIndexMap.put(nodes[size - 1], -1);
distanceMap.remove(nodes[size - 1]);
nodes[size - 1] = null;
heapify(0, --size);
return nodeRecord;
}
/* private void insertHeapfy(Node node, int index) {
while(distanceMap.get(nodes[index]) < distanceMap.get(nodes[(index - 1) / 2])){
swap(index, (index - 1) / 2);
index = (index - 1) / 2;
}
}
private void heapfy(int index, int size) {
int left = index * 2 + 1;
while(left < size) {
int smallest = left + 1 < size && distanceMap.get(nodes[left + 1]
if(smallest == index) {
break;
}
swap(smallest,index);
index = smallest;
left = index * 2 + 1;
}
}
*/
//node是否进过堆
private boolean isEntered(Node node) {
return heapIndexMap.containsKey(node);
}
//node是否在堆中
private boolean inHeap(Node node) {
return isEntered(node) && heapIndexMap.get(node) != -1;
}
private void swap(int index1, int index2) {
heapIndexMap.put(nodes[index1], index2);
heapIndexMap.put(nodes[index2], index1);
Node tmp = nodes[index1];
nodes[index1] = nodes[index2];
nodes[index2] = tmp;
}
}
//从head出发,到达每个节点的最小值,存放在哈希表中
public static HashMap<Node, Integer> dijkstral2(Node head, int size) {
NodeHeap nodeHeap = new NodeHeap(size);
nodeHeap.addOrUpdateOrIngnore(head, 0);
HashMap<Node, Integer> result = new HashMap<>();
while(!nodeHeap.isEmpty() ){
NodeRecord record = nodeHeap.pop();
Node cur = record.node;
int distance = record.distance;
for(Edge edge : cur,edges) {
nodeHeap.addOrUpdateOrIngnore(edge.to, edge.weight + distance)
}
result.put(cur, distance);
}
return result;
}Floyd算法
/**
A是存放距离的二维数组(矩阵)
path是存放中转点的矩阵
*/
for (int k = 0; k < n; k++) {//考虑以A[k]作为中转点
for (int i = 0; i < n; i++){
for (int j = 0; j < n; j++){
if ( A[i][j] > A[i][k] + A[k][j]){//以k为中转点是否会更短
A[i][j] = A[i][k] + A[k][j];//更新路径长度
path[i][j] = k;//记录中转点
}
}
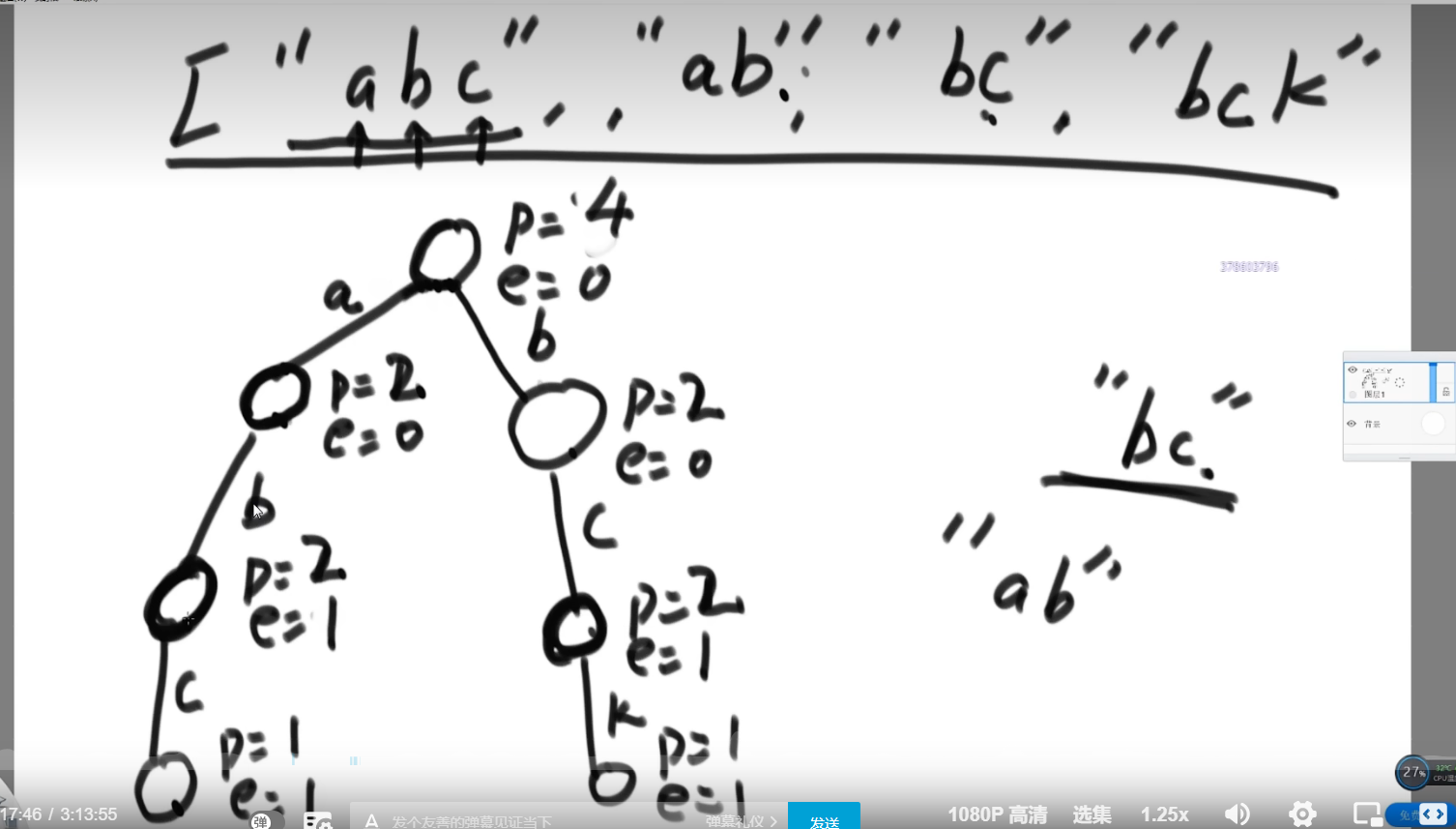
}前缀树
点的定义
class TrieNode{
public int pass;//通过多少次
public int end;//结尾节点
public TrieNode[] nexts;//HashMap<Char,Node> nexts;
public TrieNode(){
pass = 0;
end = 0;
nexts = new TrieNode[26];
//用nexts[0]是否等于0判断是否有走向‘a’的路
}
}
前缀树的定义
//前缀树的类定义
class Trie{
TrieNode root;
public Trie(){
root = new TrieNode();
}
//插入方法
public void insert(String word){
if (word == null){
return;
}
char[] chs = word.toCharArray();
TrieNode node = root;
node.pass++;
int index = 0;
for (int i = 0;i < chs.length;i++){//从左往右遍历字符
index = chs[i] - 'a';//由字符,对应成走向哪条路
if (node.nexts[index] == null){
node.nexts[index] == new TrieNode();
}
node = node.nexts[index];
node.pass++;
}
node.end++;
}
//删除方法
public void delete(String word){
if( search(word) != 0){//确认有这个字符串才能删除
char[] chs = word.toCharArray();
TrieNode node = root;
node.pass--;
int index = 0;
for (int i = 0;i < chs.length;i++){
index = chs[i] - 'a';
if (--node.nexts[index].pass == 0){
node.nexts[index] = null;
}
node = node.nexts[index ];
}
node.end--;
}
}
//查询这个字符串一共加入有几次
public int serach(String word){
if (word == null){
return 0;
}
char[] chs = word.toCharArray();
TrieNode node = root;
int index = 0;
for (int i = 0;i < chs.length;i++){
index = chs[i] - 'a';
if (node.nexts[index] == null){//如果下一个路没有,直接返回0,未加入过
return 0;
}
node = node.nexts[index];
}
return node.end;
}
//查询以这个指定字符串为前缀
public int prefixNum(String word){
if (word == null){
return 0;
}
char[] chs = word.toCharArray();
TrieNode node = root;
int index = 0;
for (int i = 0;i < chs.length;i++){
index = chs[i] - 'a';
if (node.nexts[index] == null){
return 0;
}
node = node.nexts[index];
}
return node.pass;
}
}